(서울=연합뉴스) 조성미 기자 = 지난주 미국 라스베이거스에서 열린 세계 최대 IT·가전 전시회 'CES 2025'에서 가장 화려한 스포트라이트를 받았던 행사는 젠슨 황 엔비디아 최고경영자(CEO)의 기조연설이었다.
인공지능(AI) 칩 선두 주자 엔비디아를 이끄는 수장이 다가오는 로봇과 자율주행 시대를 위한 플랫폼 '코스모스(Cosmos)'를 공개하자 전 세계 정보통신업계 시선이 라스베이거스에 쏠렸다.
CES 기조연설하는 엔비디아 젠슨 황 CEO (라스베이거스=연합뉴스) 신현우 기자 = 세계 최대 가전·정보기술(IT) 전시회 CES 2025 개막을 하루 앞둔 6일 오후(현지시간) 미국 네바다주 라스베이거스 만달레이베이 컨벤션센터 내 미셀로브 울트라 아레나(Michelob Ultra Arena)에서 젠슨 황 엔비디아 최고경영자(CEO)가 CES 기조연설을 하고 있다.2025.1.7 nowwego@yna.co.kr
젠슨 황은 "로봇의 챗GPT 모멘트가 온다"면서 코스모스는 이를 뒷받침할 '월드 파운데이션 모델'(World Foundation Model)이라고 했다.
오픈AI가 챗GPT를 공개한 뒤 거대언어모델(LLM)인 AI가 화제의 중심이 됐고, 구글, 마이크로소프트, 메타 등 내로라하는 빅테크들이 더 성능 좋고 이용하기 편한 LLM 모델과 서비스를 만들기 위해 치열한 경쟁을 벌이고 있다.
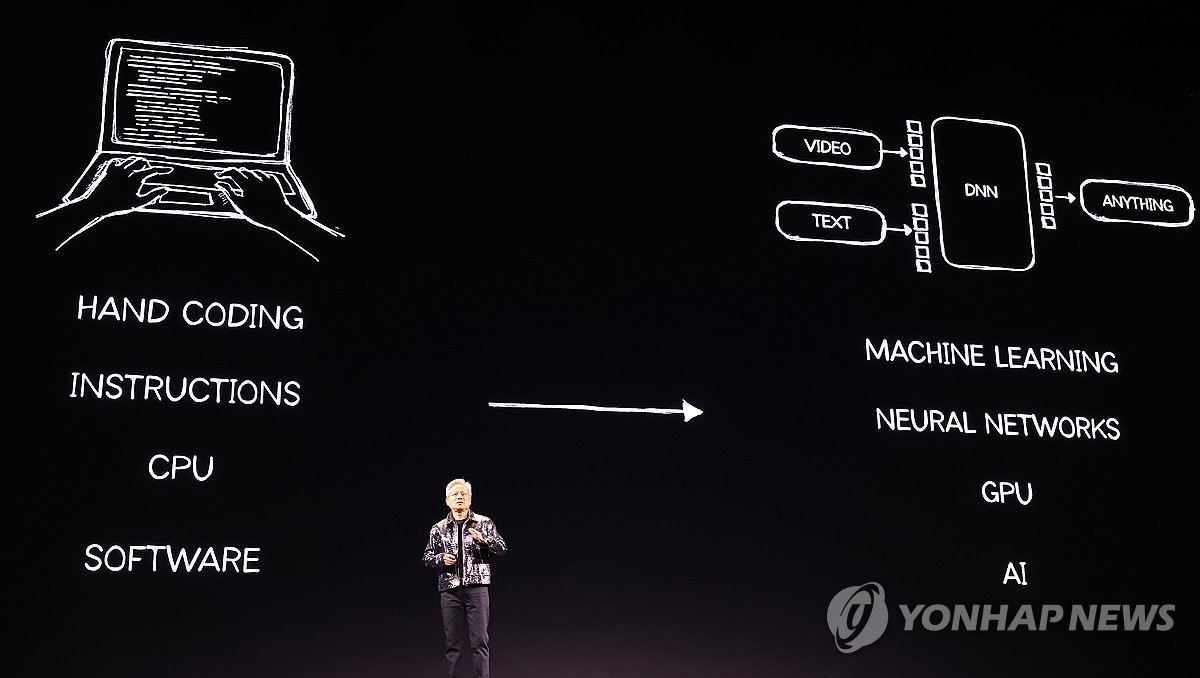
하지만, LLM이 초기 단계 AI 모델일 뿐이어서 AI 업계는 이제 '언어'를 넘어 실물(피지컬) 세계에서 작동하는 AI의 유용성에 눈을 돌리고 있다.
가령, LLM이 보고서 초안을 작성하고 방대한 데이터를 일목요연하게 정리해준다 해도 이는 컴퓨터 화면 속 문서 세계의 활동에서 벗어나지 못한다.
AI가 자동차를 운전하게 하고 로봇에게 사람을 대신해 작업을 지시할 수 있도록 하는 데 LLM의 역할은 미미하다는 이야기다.
AI를 물리 세계에서 써먹으려면 문자나 음성 텍스트가 아닌 영상이나 이미지를 학습하고 결괏값을 생성할 수 있는 '영상언어모델'(VLM)이 필요하다.
자율주행차가 교차로에서 차량, 보행자의 움직임 데이터를 학습해 사고가 나지 않도록 피하게 하고, 로봇이 스마트 팩토리의 제조 공정에서 필요한 작업을 수행할 수 있게 하려면 VLM이 필수적이다.
젠슨 황이 공개한 코스모스 플랫폼은 문자 텍스트보다 데이터양이 압도적으로 많은 영상을 VLM이 학습할 수 있게 하는 플랫폼이다.
이 플랫폼은 2천만 시간 분량의 영상을 단 14일 만에 처리한다고 한다.
중앙처리장치(CPU)만 사용하는 경우 3.4년이 걸리는 분량이다.
영상을 학습하고 데이터를 생성하는 데 유용한 VLM은 나아가 사람이 말(자연어)로 한 명령을 로봇, 자동차 등이 따르도록 하는 'VLA'(영상 언어 액션모델) 단계로 고도화되고 있다.
황병준 유안타증권[003470] 연구원은 "피지컬 AI 구현을 위해 AI 모델 고도화 수요가 증가하면서 차세대 AI 반도체 아키텍처 및 인프라 소프트웨어 수요가 증가할 전망"이라고 내다봤다.